AI Infrastructure and Operations
Essential AI Knowledge – Study Guide
Exam Weight: 38%
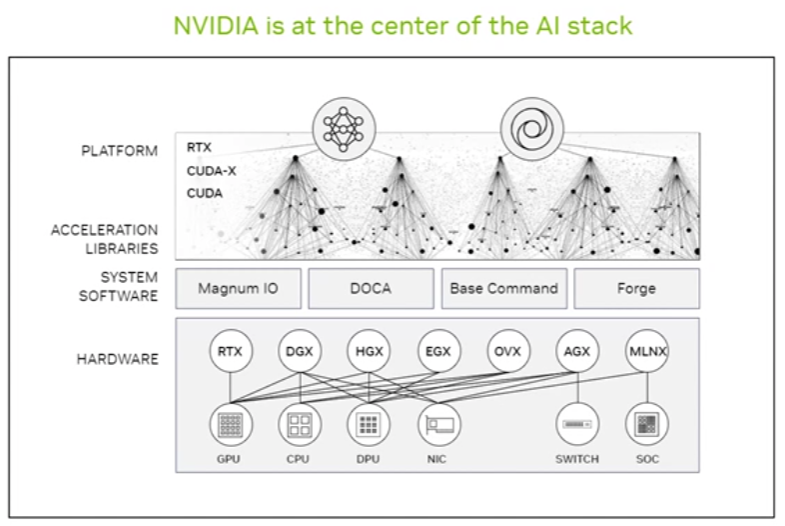
1.1 Describe the NVIDIA software stack used in an AI environment
🔹 Key Components:
- CUDA: Parallel computing platform enabling GPU acceleration.
- cuDNN: Deep Neural Network library for optimized primitives (e.g., convolutions).
- TensorRT: High-performance inference optimizer for deep learning.
- NVIDIA Triton Inference Server: Serves AI models for inference with support for multiple frameworks (TensorFlow, PyTorch, ONNX).
- NVIDIA RAPIDS: Suite of data science and analytics libraries using CUDA for acceleration.
- NVIDIA AI Enterprise: End-to-end AI and data analytics software suite certified for VMware, Red Hat, etc.
- NGC Catalog: Registry of pre-trained models, SDKs, containers, and Helm charts.
🛠️ Practical Example:
Train with PyTorch using CUDA backend → Optimize model with TensorRT → Deploy via Triton.
1.2 Compare and contrast training and inference architecture requirements and considerations
Training:
- Hardware Needs: More compute, memory, multi-GPU support (e.g., NVIDIA A100).
- Precision: Often uses FP32 or mixed precision (FP16+FP32).
- Duration: Time-consuming and resource-intensive.
- Frameworks: TensorFlow, PyTorch, JAX.
Inference:
- Hardware: Can run on edge devices (Jetson) or optimized servers (T4, L4).
- Precision: INT8 or FP16 for performance.
- Goal: Low latency, high throughput.
- Tools: TensorRT, Triton, DeepStream (video).
1.3 Differentiate the concepts of AI, machine learning, and deep learning
| Concept | Description | Example |
|---|---|---|
| AI (Artificial Intelligence) | Simulating intelligent behavior in machines | Chatbots, recommendation engines |
| ML (Machine Learning) | Subset of AI where machines learn from data | Spam filters, fraud detection |
| DL (Deep Learning) | Subset of ML using neural networks with many layers | Image recognition, speech synthesis |
Mnemonic: AI ⊇ ML ⊇ DL
1.4 Explain the factors contributing to recent rapid improvements and adoption of AI
Key Drivers:
- Hardware Advances: GPUs (NVIDIA A100, H100), Tensor Cores, NPUs.
- Big Data Availability: Massive labeled/unlabeled datasets.
- Open Source Ecosystem: PyTorch, TensorFlow, Hugging Face, ONNX.
- Cloud AI: On-demand access to powerful infrastructure (AWS, GCP, Azure).
- NVIDIA Ecosystem: End-to-end tools and pretrained models accelerate dev time.
1.5 Explain the key AI use cases and industries
Industries:
- Healthcare: Diagnostics, drug discovery (e.g., Clara)
- Finance: Fraud detection, algorithmic trading
- Retail: Personalized ads, inventory optimization
- Manufacturing: Predictive maintenance, defect detection
- Transportation: Autonomous vehicles (NVIDIA Drive)
Use Cases:
- Natural Language Processing (NLP)
- Computer Vision
- Speech Recognition
- Recommender Systems
- Generative AI (e.g., ChatGPT, Stable Diffusion)
1.6 Explain the purpose and use case of various NVIDIA solutions
| NVIDIA Solution | Use Case |
|---|---|
| NVIDIA Jetson | Edge AI, robotics |
| NVIDIA Drive | Autonomous vehicles |
| NVIDIA Clara | AI in healthcare/medical imaging |
| NVIDIA Metropolis | Smart cities, video analytics |
| NVIDIA Omniverse | 3D collaboration and digital twins |
| NVIDIA DGX Systems | AI supercomputers for training |
| NVIDIA cuOpt | Route and logistics optimization |
| Triton Inference Server | Model deployment and serving |
1.7 Describe the software components related to the life cycle of AI development and deployment
AI Development Lifecycle:
- Data Collection & Labeling: Tools: NVIDIA TAO Toolkit, CVAT
- Model Training: CUDA, cuDNN, PyTorch/TensorFlow, NVIDIA DGX
- Optimization: TensorRT, Quantization (FP16/INT8)
- Deployment: Triton Inference Server, Jetson
- Monitoring & Feedback: NVIDIA AI Enterprise (with MLOps tools)
Tip: AI dev cycle is iterative — improvements are constant via feedback.
1.8 Compare and contrast GPU and CPU architectures
| Feature | CPU | GPU |
|---|---|---|
| Core Count | Few powerful cores | Thousands of simple cores |
| Parallelism | Good at sequential tasks | Excellent at parallel tasks |
| Use Case | General-purpose computing | Matrix operations, ML/DL workloads |
| Throughput | Low for AI tasks | High throughput for AI/ML |
| Examples | Intel i9, AMD Ryzen | NVIDIA A100, RTX 4090 |
📌 Takeaway: CPUs are brains; GPUs are muscles in AI workloads.
✅ Pro Tips for the Exam
- Memorize key NVIDIA tools and match them to their use cases.
- Understand AI lifecycle stages and what NVIDIA products are used when.
- Be able to explain why GPUs accelerate AI compared to CPUs.
- Practice comparing INT8 vs FP16 vs FP32 and how inference vs training differ.
- Know the NVIDIA NGC Catalog — it’s a hub for models, containers, and more.
AI Infrastructure – Study Guide
Exam Weight: 40%
2.1 Extracting Insights from Large Datasets
Techniques to Know:
- Data Mining: Uncover patterns from raw data (e.g., clustering, association rules).
- Data Visualization: Graphically represent trends/patterns (matplotlib, seaborn, Tableau).
- ETL Process: Extract, Transform, Load – essential for data prep.
- Dimensionality Reduction: PCA, t-SNE for high-dimensional datasets.
- Descriptive vs Inferential Analysis:
- Descriptive: Summarize data (mean, median, mode).
- Inferential: Draw conclusions beyond the data (e.g., hypothesis testing).
📌 Tool Stack:
- Python (pandas, numpy, matplotlib, scikit-learn)
- SQL
- NVIDIA RAPIDS (GPU-accelerated data science)
2.2 Comparing Models Using Statistical Metrics
Key Metrics:
| Metric | Description |
|---|---|
| Loss Functions | Measure error (e.g., MSE, Cross-Entropy) |
| Accuracy / Precision / Recall / F1 | Classification quality |
| Explained Variance | How much of the outcome variance is explained by the model |
| AUC-ROC / PR Curves | Evaluation under imbalance |
| R² (R-squared) | Goodness of fit for regression |
Tip: Select metrics based on your model type (classification vs regression).
2.3 Conducting Data Analysis Under Supervision
Real-World Application:
- Junior analysts often:
- Clean and prepare data.
- Create draft reports or dashboards.
- Follow analysis protocols set by senior staff.
- Key Skills:
- Ask clarifying questions.
- Version control with Git.
- Maintain data lineage (understand source and transformations).
- Use Jupyter Notebooks for transparency.
2.4 Creating Visualizations Using Specialized Software
Tools to Master:
- Python: matplotlib, seaborn, Plotly
- BI Tools: Power BI, Tableau, Google Data Studio
- GPU Tools: NVIDIA RAPIDS cuDF + cuGraph, Holoviews
Visualization Types:
- Histograms, bar charts, scatter plots
- Line graphs (trend analysis)
- Heatmaps (correlation matrix)
- Box plots (distribution analysis)
📌 Tip: Choose the right chart based on data type (categorical vs continuous).
2.5 Identifying Relationships and Trends
Techniques:
- Correlation Analysis (Pearson, Spearman)
- Time Series Analysis (rolling mean, trend decomposition)
- Outlier Detection (z-score, IQR)
- Regression Models (linear, logistic, multiple)
- Clustering (K-means, DBSCAN)
Interpretation Goals:
- Identify variables that predict outcomes.
- Spot anomalies or shifts.
- Explain causality (when possible).
Recommended Units (from Course)
| Unit | Topic |
|---|---|
| Unit 4 | Accelerating AI with GPUs |
| Unit 7.1 | Data Center Platforms |
| Unit 7.4 | NVIDIA DPUs & Transformation |
| Unit 8 | Networking for AI |
| Unit 10 & 11 | Energy-Efficient Computing |
| Unit 12.4 | AI in the Cloud Considerations |
📌 Key Terms to Know:
- DPU: Data Processing Unit (offloads networking/storage workloads)
- GPU Acceleration: Speeding up data processing & ML
- Cloud vs On-Prem Infrastructure
- Energy Efficiency: Thermal design, compute density, carbon cost
✅ Pro Tips for the Exam
- Understand how GPU-powered infrastructure supports AI workloads.
- Practice interpreting loss curves, graphs, and model metrics.
- Use real-world data for mini projects (e.g., Kaggle datasets).
- Familiarize with cloud-native tools (e.g., containers, DPU offloading).
- Be ready to compare CPU vs GPU vs DPU roles in AI pipelines.
AI Operations – Study Guide
Exam Weight: 22%
3.1 AI Data Center Management & Monitoring Essentials
Key Concepts:
- Telemetry: Collect real-time metrics (temperature, power usage, memory, compute load).
- Monitoring Tools:
- NVIDIA DCGM (Data Center GPU Manager): GPU health, diagnostics, telemetry.
- Prometheus + Grafana: Time-series monitoring dashboards.
- Nagios / Zabbix: General infrastructure health tracking.
Best Practices:
- Automate alerts for failures (GPU overheat, memory errors).
- Track power consumption and cooling status.
- Segment logging by node or cluster.
3.2 Cluster Orchestration & Job Scheduling
Essential Components:
- Cluster Orchestration:
- Kubernetes (with GPU support via
nvidia-device-plugin) - SLURM (Simple Linux Utility for Resource Management)
- Kubernetes (with GPU support via
- Job Scheduling:
- Assigns resources based on availability and priority.
- Supports queues, time limits, and preemption.
Concepts to Know:
- Pod vs Job vs Deployment (in Kubernetes)
- Resource quotas, node affinity, GPU allocation policies
- Multi-tenancy and fair usage enforcement
3.3 Monitoring GPU Metrics & Performance
Key Metrics:
| Metric | Description |
|---|---|
| GPU Utilization | % of time GPU is actively processing |
| Memory Usage | VRAM consumption |
| Power Draw | Measured in watts |
| Thermal Data | Temperature trends |
| ECC Errors | Memory integrity events |
📌 Tools:
nvidia-smi(CLI)- DCGM CLI and DCGM Exporter
- Integrated cloud GPU dashboards (e.g., GCP, AWS)
3.4 Virtualizing Accelerated Infrastructure
Key Concepts:
- GPU Virtualization Types:
- vGPU (NVIDIA GRID): Multiple VMs share one physical GPU.
- Passthrough (PCIe): One VM gets exclusive GPU access.
- Use Cases:
- Enterprise VDI (Virtual Desktop Infrastructure)
- Remote AI/ML environments
- Requirements:
- Compatible hypervisor (e.g., VMware ESXi with vGPU manager)
- NVIDIA vGPU Software License
- GPU supporting virtualization (e.g., A40, A100)
Recommended Units (Course Reference)
| Unit | Topic |
|---|---|
| Unit 5 | AI Software Ecosystem |
| Unit 8 | Networking for AI |
| Unit 13 | AI Data Center Management and Monitoring |
| Unit 14 | Orchestration, MLOps, and Job Scheduling |
✅ Pro Tips for the Exam
- Memorize core tools like
nvidia-smi, DCGM, and Kubernetes job lifecycle. - Understand GPU metric thresholds (normal vs high temp, power).
- Know virtualization trade-offs: performance vs density.
- Link monitoring → orchestration → infrastructure for full-stack AI ops insight.
